又是很久没有写博客了,最近忙着一个开源项目,做一个免费漫画app,抓取网易和腾讯漫画的web数据,用nodejs+koa+mongoose+socket.io搭建这个app的后端服务,客户端用react-native编写,同时适配ios和Android。本人是做Android开发的,想借此机会打开全栈技术的大门,给自己的技术栈增加一些广度。对于一个app开发者来说,app的数据源总是一个很头疼的问题,虽然现在免费的api接口有很多,但是类型就那么几种,想做一些感兴趣的app但是苦于找不到数据源。之前学react-native的时候也做过一个开源项目高仿韩寒的one一个SimpleOne传送门,这个app的数据全是通过抓包工具抓取官方app的接口地址(用charles或fidder即可),分析数据获得,由于数据没有做加密,所以没有花太多的成本。但是毕竟是别人的接口,出现问题不是自己可控的。后来了解到google的一个web自动化测试框架puppeteer,解析html抓取dom节点,这下就可以通过服务端访问web,抓取数据,提供接口将抓取到的数据返回给客户端,做自己感兴趣的应用了。而且自己本来对服务端的技术也感兴趣,索性借此机会学下nodejs相关的服务端技术。下面就对puppeteer这个自动化框架爬虫做一个入门总结,接触不久,如有不对的地方欢迎指正。
puppeteer框架背景
puppeteer是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,它是一个 Node 库, web 应用自动化测试框架,提供了一些高级的 API 来控制Chrome浏览器。你也可以在开发过程中开启浏览器,实时查看运行过程方便调试。那它可以做写什么呢?
- 生成页面的截图和PDF。
- 抓取SPA并生成预先呈现的内容(即“SSR”)。
- 从网站抓取你需要的内容。
- 自动表单提交,UI测试,键盘输入等
- 创建一个最新的自动化测试环境。使用最新的JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试。
- 捕获您的网站的时间线跟踪,以帮助诊断性能问题。
为什么要选择puppeteer?
nodejs的爬虫框架有很多,要根据具体的业务进行选择,比如说cheerio一类的静态网页爬虫框架就只能爬取服务端渲染的网页,不能爬取JavaScript运行后的数据,但很多时候我们需要爬取的是动态网页,而puppeteer可以完整的模拟浏览器获取网页,访问dom,且框架的运行效率也很不错,
支持调用Chrome的API来操纵Web,相比较Selenium或是PhantomJs,它最大的特点就是它的操作Dom可以完全在内存中进行模拟既在V8引擎中处理而不打开浏览器,是Chrome团队在维护,拥有更好的兼容性和前景。
puppeteer如何使用?
安装puppeteer
这里有个安装的坑,别看puppeteer的安装只有npm i puppeteer这么一条简单的命令,但是在国内安装起来也不是这么容易的,因为它默认会去下载Chromium作为抓取数据的客户端,国内基本下载不下来,安装会失败。即使我开着ss,仍然失败了,Orz….比如说像下面这样报错
1 | ERROR: Failed to download Chromium r515411! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOA |
我发现从最新的1.7的版本开始分离出一个轻量版的puppeteer核心库,默认不去下载Chromium。
当然网上也有很多教程说先忽略跳过,再去手动下载Chromium,后面可能还有一些坑要跳,个人感觉比较麻烦,这里有一个方便快捷的办法。无意中发现一个库puppeteer-cn传送门,和puppeteer完全一样,你完全可以用puppeteer-cn代替之。这个包会先去检测本地Chrome版本是否大于59,再决定是否通过一个国内源下载Chromium。这个库下载速度很快,直接就安装好了Chromium。
使用puppeteer
这个无非是一些常规的API调用,可以查阅官方的文档来实现一些自己想要的功能,这里给出一个快速上手的小例子。由于我的app是抓取免费漫画,下面就给出抓取网易免费漫画的例子
- 引入puppeteer工具类
1
const puppeteer = require('puppeteer-cn') //抓取工具类
- 设置模拟的pc设备
设置浏览器的尺寸和userAgent1
2
3
4
5
6
7
8
9
10/**
* 模拟pc设备mac
*/
const viewPort = {
width: 1920,
height: 1080
}
const userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
await page.setViewport(viewPort);
await page.setUserAgent(userAgent); - 初始化请求客户端headless 设置为true,则不展示Chromium的访问界面,在开发过程中,为了方便调试,最好设置成false,可以实时查看运行过程。
1
2
3
4// 启动了一个Chrome实例
let browser = await puppeteer.launch({ headless: true })
// 浏览器中创建一个新的页面
await browser.newPage() - 跳转到目标网站这个地址正好是网易漫画的官方地址在漫画列表中过滤出免费漫画
1
2
3
4
5let url = 'https://manhua.163.com/category?sort=2&sf=1'
// 跳转到目标网站
await page.goto(url)
// 等待时长
await page.waitFor(200) - 抓取数据,并返回
- 首先分析抓取到的页面数据,找出目标dom节点,
可以在调试的Chromium中或者在自己打开一个chrome浏览器中按下查看网页代码。
调出审查元素界面
Mac:command+option+I
windows/linux:ctrl+shift+I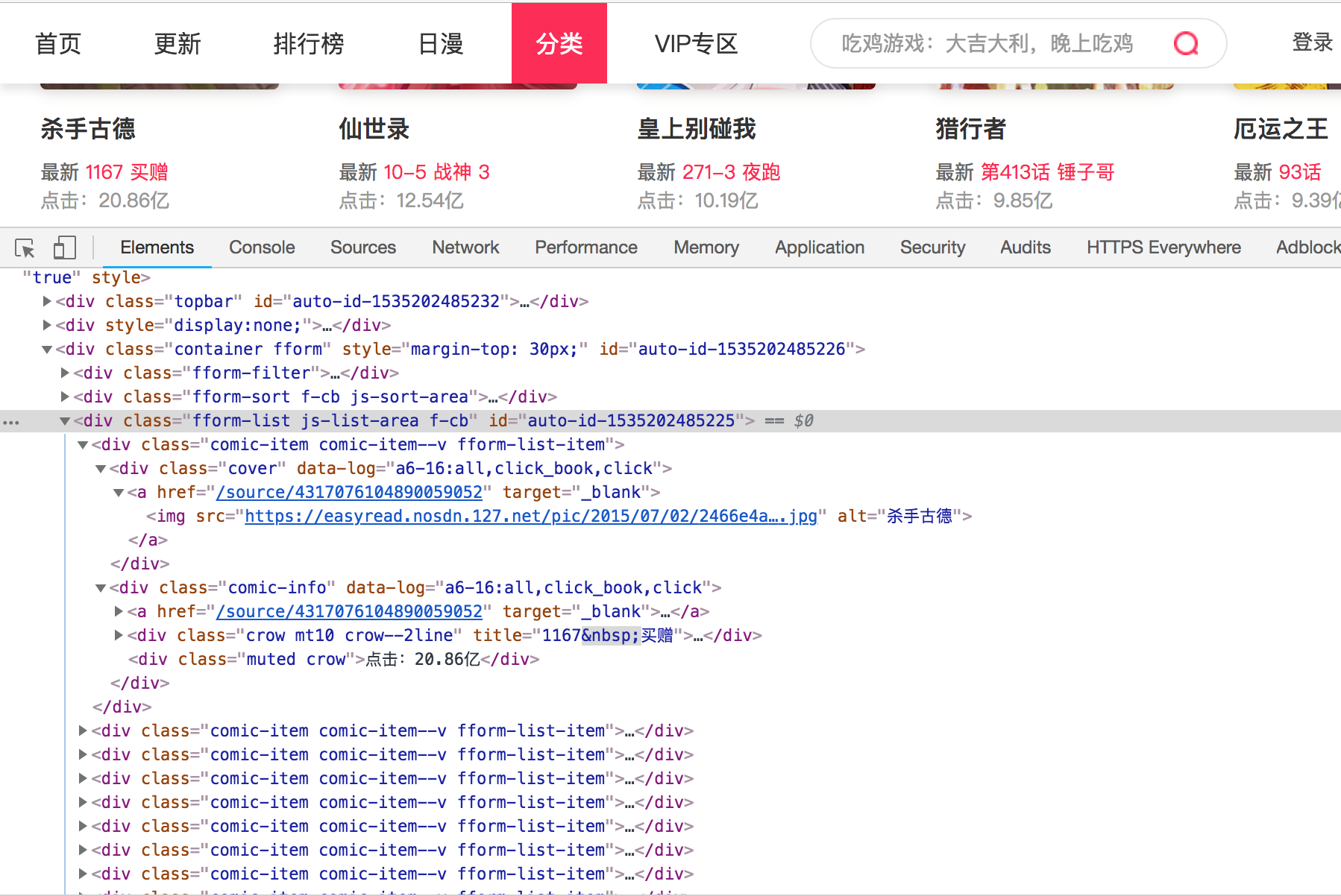
从网页代码中,我们可以找出目标数据和相关的dom节点。带有comic-item类选择器的div就是漫画列表的每一个数据项,其中子节点cover类选择器div就是数据项的图片信息部分,里面的子元素img标签的src属性就是漫画封面的图片地址。而comic-info类选择器的div就是数据项的文字信息部分,里面的子元素.title类选择器的div中包含的文字就是标题,span标签中包含的文字就是当前章节,.muted类选择器div中的文字就是点击量,漫画的跳转链接在a标签中的href属性中,得到完整的地址需要做一个拼接。
puppeteer是通过seletor选择器去获取元素的,了解一部分前端知识的人来说并不陌生,也没什么难度。分析完了以后,我们就可以从目标dom中提取到想要返回的数据。
所以最后的抓取代码如下:通过seletor选择器去获取元素,有两种方法可以获取目标节点,一个是通过page.evaluate这个api获取到html内容后,在回调函数中调用dom节点选择器相关api获取,这个回调函数无法打印log,无法内部断点,也无法直接访问外部的变量,需要通过api最后一个参数进行传参访问,最后返回一个操作结果。另一个方法就是通过puppeteer的选择器相关api直接获取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17let targetUrl = 'https://manhua.163.com'
return await page.evaluate((targetUrl) => {
let data = []
let elements = document.querySelectorAll('.comic-item') // 获取所有漫画元素
for (let element of elements) { // 循环
let title = element.querySelector('.comic-info .title').innerText // 获取标题
let chapter = element.querySelector('.comic-info span').innerText // 获取章节
let clickNum = element.querySelector('.comic-info div.muted').innerText // 获取点击量
let link = element.querySelector('.comic-info a').getAttribute('href')
link = targetUrl + link
let cover = element.querySelector('.cover img').getAttribute('src')
// let id = link.replace('https://manhua.163.com/source/','')
let id = link.substring(link.lastIndexOf('/')+1,link.length)
data.push({ id, title, chapter, clickNum, link, cover }) // 存入数组
}
return data
}, targetUrl)
比如说这样:1
2
3
4
5
6
7
8// 获取匹配选择器'div.portrait-player .img-box'下的所有节点
let imgs = await page.$$('div.portrait-player .img-box')
// 获取匹配选择器'div.portrait-player .img-box'下的第一个节点
let img = await page.$$('div.portrait-player .img-box')
// 获取匹配选择器'div.portrait-player .img-box'下的所有节点并返回数量
let imagesLen = await page.$$eval('div.portrait-player .img-box', imgs => imgs.length)
// 获取匹配选择器'div.portrait-player .img-box'下的第一个节点并返回节点的style属性中的高度值并去掉'px'单位字符串
let imgHeight =await page.$eval('div.portrait-player .img-box', img => img.style.height.replace('px',''))page.$$抓取该选择器匹配的所有节点,对应dom获取节点querySelectorAll这个api,如果没有匹配的返回nullpage.$抓取该选择器匹配的第一个节点并返回给回调函数,对应dom获取节点querySelector这个api,如果没有匹配的返回null,page.$$eval比起page.$$多了一个回调函数进行抓取后的操作,抓取该选择器匹配的所有节点并返回给回调函数,在回调函数中进行数据转换操作后再返回函数结果,如果没有匹配的是抛出一个异常page.$eval比起page.$多了一个回调函数进行抓取后的操作,抓取该选择器匹配的第一个节点并返回给回调函数,在回调函数中进行数据转换操作后再返回函数结果,如果没有匹配的是抛出一个异常
当然,puppeteer提供的api操作远不止这些,这只是一个快速上手的小例子,更多有趣的玩法,可以参考官方的文档,这里就不一一列举了。