又是很久没有写博客了,最近由于武汉疫情,这个春节从初一起就全程宅家,春节假期一延再延,本该上班的我们依然没有正常返工,街上仍然是没有几个人,快递延迟,很多人仍然是宅在家里远程上班。停工不停学,之前的漫画项目主要使用了网易漫画和腾讯漫画爬取的数据,而网易漫画在不久前被bilibili收购了,现在正式改为bilibili漫画,所以之前的爬虫逻辑和接口失效了,正好趁着这个时间把之前的服务端数据爬取接口改一下,这里做一个简单的记录。
爬取漫画列表和漫画详情都没什么问题,跟之前的思路一样,改一下对应的标签重新绑定目标数据,但是在爬去漫画内容的时候,发现漫画图片的链接已经不在html的标签中了,而是直接获取到服务端返回的图片地址后用canvas绘制出来的。如下图所示: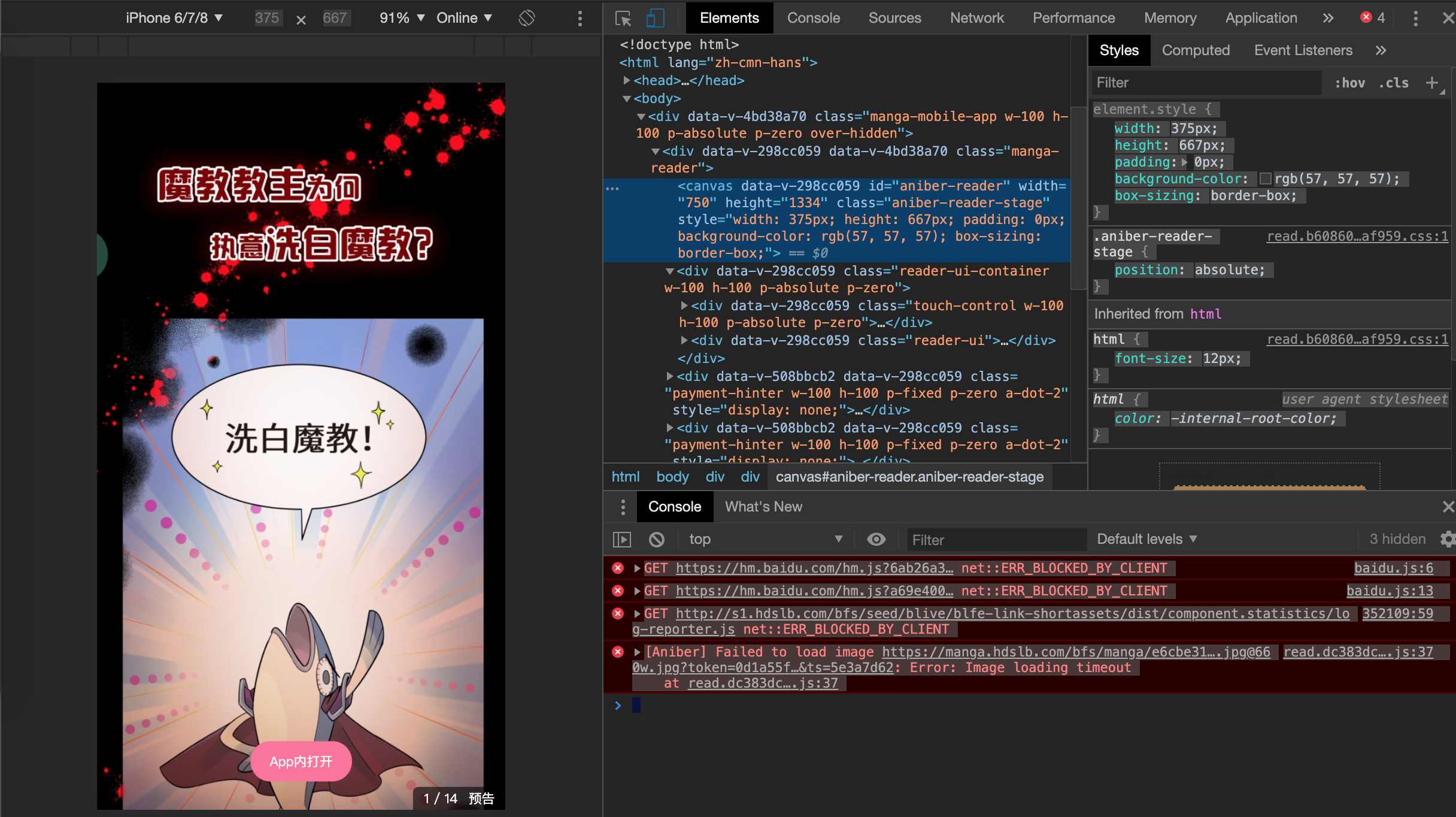
所以只要我们能获取到该页面的网络请求结果,我们就能过滤出图片地址,也就不用去标签中获取目标数据了,接下来我发现在chrome浏览器中元素审查界面的网络拦截器中可以找到漫画内容的图片链接,如下图所示: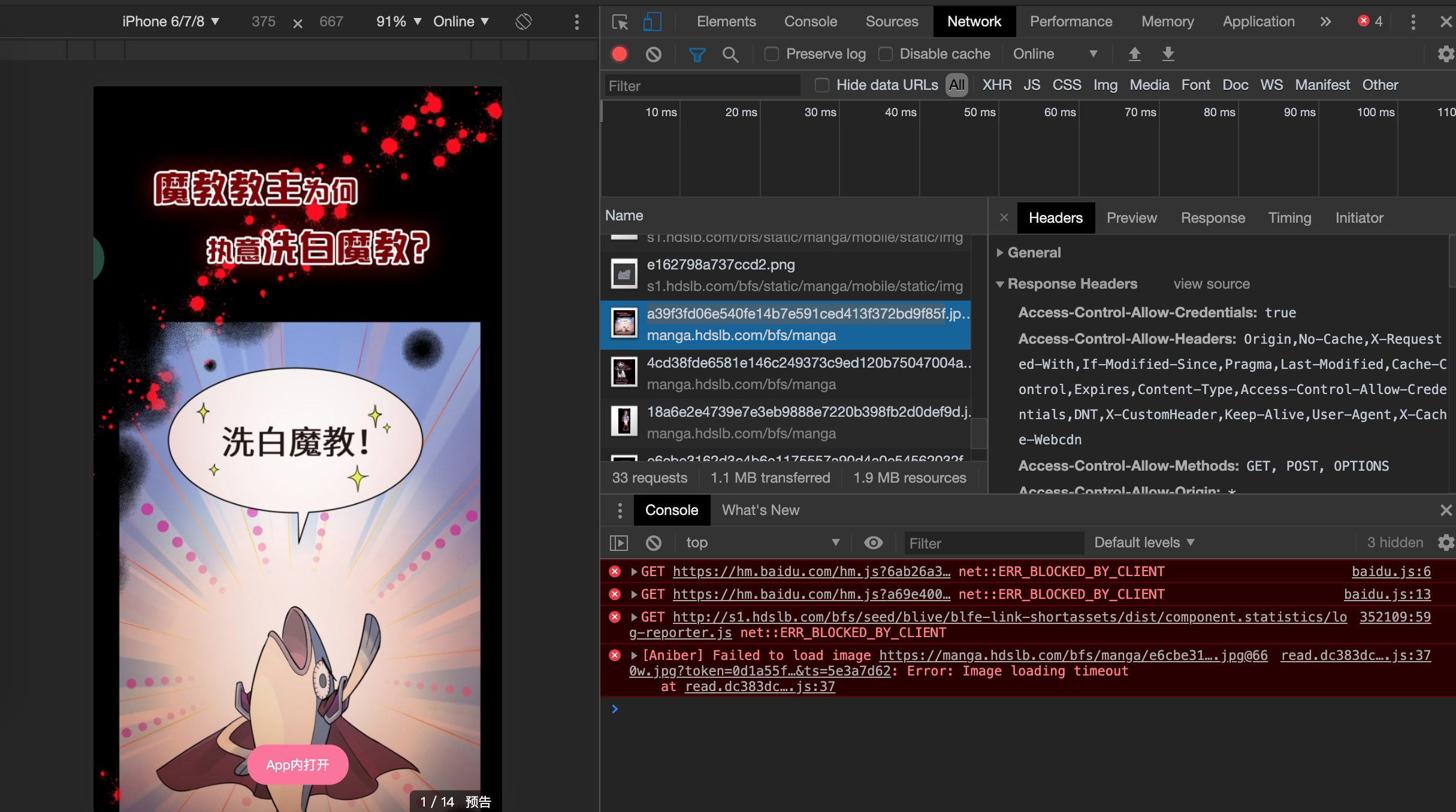
所以只要我们目前使用的爬虫框架puppeteer能够拦截到网络请求的结果就可以解决标签中无法爬取到图片地址的问题了。我查了一下puppeteer的官方文档,发现了这些api
开启拦截
page.setRequestInterception(true)
监听服务端返回page.on('response')
另外还可以监听当前页面的请求
page.on('request')
返回一个自定义的响应
req.respond()
根据当前的场景,我们需要获取服务器返回的数据,并过滤其中的漫画图片地址
https://manga.hdslb.com/bfs/manga/a39f3fd06e540fe14b7e591ced413f372bd9f85f.jpg@660w.jpg?token=3a96fd02961137c00a76145fb381d544&ts=5e3a7d62
https://manga.hdslb.com/bfs/manga/4cd38fde6581e146c249373c9ed120b75047004a.jpg@660w.jpg?token=2e740fd7ccfefec3f1f5d0d27e925e33&ts=5e3a7d62
https://manga.hdslb.com/bfs/manga/18a6e2e4739e7e3eb9888e7220b398fb2d0def9d.jpg@660w.jpg?token=0e8b573c3c40fa3c5554d2df6ec8b2cb&ts=5e3a7d62
https://manga.hdslb.com/bfs/manga/e6cbe3162d3c4b6e1175557a90d4a0e54562032f.jpg@660w.jpg?token=0d1a55fe1d27d3527a9340034cd5a35f&ts=5e3a7d62
https://manga.hdslb.com/bfs/manga/0c649ad9107997801dd4e45179323381b16dc50a.jpg@660w.jpg?token=fbdf6eb7df231dbe345f4411a32d56c6&ts=5e3a7d62
以上的链接地址特征
- 以
https://manga.hdslb.com/bfs/manga/开头 - 尾部都跟有token和ts的参数,
?token=和&ts= @660w.jpg看起来是传入了请求图片的宽度和图片格式- 抛开
@后面的尾部参数,请求的图片格式和@后面的尾部参数传入的格式一致
根据特征,抓取漫画图片代码如下:
1 | const puppeteer = require('puppeteer') |